
Significance Statement
Methods surrounding data compression are normally implemented in signal processing field including robust estimation of minor as well as principle components of a stochastic signal, color image watermarking, image resolution enhancement, similarity search in several signals, and multisensory networks. In a normal case of stochastic, data compression is realized through transformations of random vectors. In the current study, new methods for transforms of random vectors have been explored and justified.
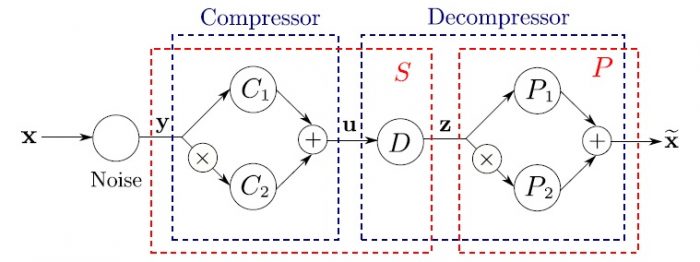
In a bid to adequately describe a device of the proposed transforms, the broad terms generic Karhunen-Loeve, Brillinger transform and second Karhunen-Loeve transform have to be taken into account. The Brillinger and Karhunen-Loeve transforms appear from a solution of a single optimization problem with mxn parameters to optimize and are entries of matrix F. These have one degree of freedom to enhance the related precision. For this reason, for a fixed compression ration c, their precision cannot be improved.
The second generic Karhunen-Loeve transform has two degrees of freedom, k and one matrix as compared to the first transform. Therefore, the second transform has twice as many parameters to optimize than the first transform and the Brillinger transform. This allows for an improvement of the precision needed for both Karhunen-Loeve and Brillinger transforms.
Pablo Soto-Quiros and Anatoli Torokhti at the University of South Australia constructed a transform as a combination of various optimal transforms that followed from solutions at varying optimization problems. Therefore, the proposed combined transform had more parameters to optimize and a number of degrees of freedom to enhance its performance. Above all, it allowed the authors to increase the associated accuracy in decomposed data. These transforms are effective in the case of quite noisy signals. Their work is published in peer-reviewed journal, Signal processing.
The authors proposed and justified the new transform T. This transform was called the second-degree Brillinger-like transform with single consecutive filtering. It was indicated that the generic Brillinger transform was applicable to instances where the Brillinger transform was not. This may be because the generalized Brillinger transform was given in terms of the pseudo-inverse matrices, not in inverse matrices. The generic Brillinger had little numerical load as compared to generic Karhunen-Loeve transform.
The second-degree Brillinger-like transform provided better-associated accuracy than that of the generic Brillinger transform. For this reason, the T transform offered better accuracy in signal recovery. The outstanding feature of the proposed method is a combination of particular advantages on its integral parts.
The authors proposed and justified a new method for the construction of random vectors. These transforms were used for data compression, which is heavily implemented in fields of signal processing. The basic idea was to come up with the transform as a combination of various transforms. This device allowed the authors to improve the number of parameters to optimize and by extension, enhance the associated accuracy.
Soto-Quiros and Torokhti proved that the accuracy of the proposed transform improved as parameter q increased. The generic Brillinger transform and second order Brillinger transform were important in their own right. They extended the known transform by Brillinger so that the generic brillinger transform provided a range of applicability than the Brillinger and less numerical load than the generic Karhunen-Loeve for the same compression ratio and precision.



Reference
Pablo Soto-Quiros and Anatoli Torokhti. Optimal transforms of random vectors: The case of successive optimizations. Signal Processing, volume 132 (2017), pages 183–196.
Go To Signal Processing