Significance
When vibration signals from rotating machinery evolve under fluctuating loads, the statistical relationship between extracted features and discrete fault labels often drifts in ways that static classifiers fail to track. The mapping from time–frequency descriptors to health states is not fixed; it deforms as operating speed, torque, or radial force change. In mechanical fault diagnosis, that deformation exposes a persistent tension: models with strong expressive power typically require extensive retraining when new data arrive, yet industrial systems generate data incrementally, not in a single curated batch. Deep architectures have dominated intelligent diagnosis, largely because of their capacity to approximate nonlinear mappings with high accuracy. That capacity, however, comes at a cost. Large parameter counts, sensitivity to hyperparameters, and the assumption of complete datasets at training time limit their deployment in environments where memory, computation, or annotation budgets are constrained. Incremental variants of support vector machines, extreme learning machines, and broad learning systems attempt to mitigate retraining overhead, but they remain algorithmically motivated constructions. Their update rules are engineered; they are not derived from a structural theorem about the function space in which the signal–label mapping resides. A recent research paper published in Mechanical Systems and Signal Processing and conducted by Dr. Xianbin Zheng, Dr. Zhengyang Cheng, Professor Junsheng Cheng, and Professor Yu Yang from the Hunan University and Professor Chitin Hon from Macau University of Science and Technology, the authors developed a Blaschke Learning Machine grounded in a formal Blaschke approximation theorem that guarantees optimal n-order representation of unknown mappings within the unit disk. They designed dynamic Blaschke and enhancement nodes whose parameters update incrementally through Greville-based pseudoinverse formulas, avoiding full retraining. They integrated SVD truncation for numerical stability and SAFD-based node pre-initialization with Fisher score filtering for condition adaptation.
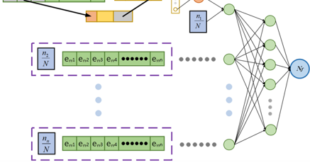
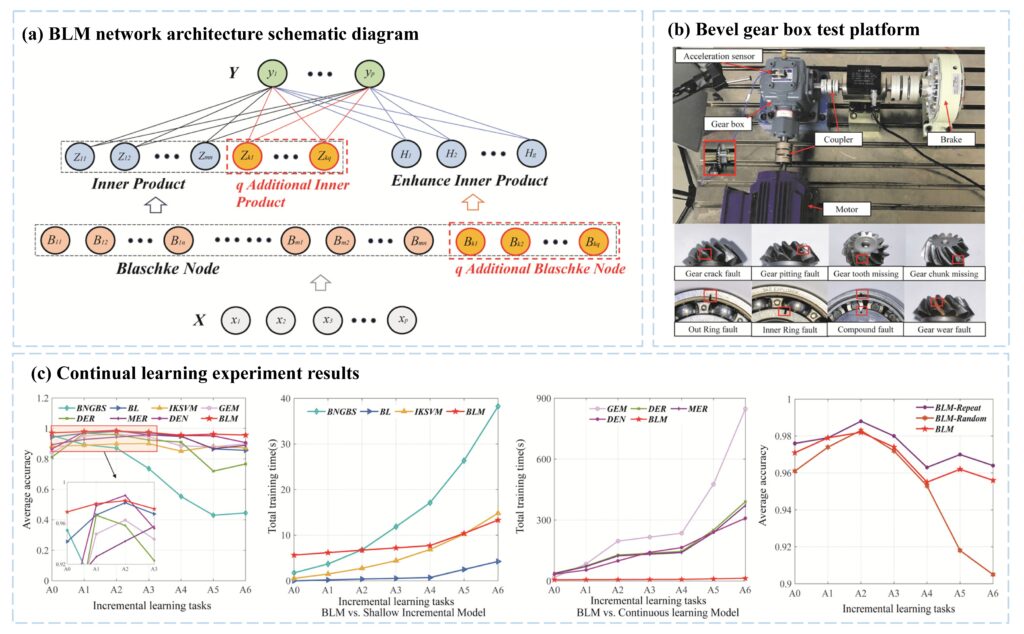
The research team formalized the Blaschke approximation theorem by proving that for any unknown mapping F, either a finite Blaschke system generated by parameters in the unit disk exactly represents F, or an n-term expansion attains the minimal L² error among all n-Blaschke forms. That theoretical result allowed them to construct the Blaschke Learning Machine by generating rows of complex parameters within the unit disk, each row defining a weighted Blaschke product that serves as a node. Instead of stacking layers in depth, they computed inner products between input signals and these Blaschke nodes, forming a structured projection matrix. They then introduced nonlinear enhancement through random mappings applied to the inner-product matrix, after which they solved the output weights via ridge regression. This design preserved the shallow character of the network while embedding a mathematically interpretable decomposition at its core. When the initial configuration failed to reach a predefined accuracy threshold, the investigators expanded the architecture by adding either enhanced inner-product nodes or additional Blaschke nodes, updating the pseudoinverse through the Greville theorem. Because the Greville update reuses existing inverse information, they avoided full retraining; the update cost scaled with the increment, not with the entire dataset. That choice directly tied computational efficiency to the algebraic properties of generalized inverses. The team recognized that numerical instability could arise when the condition number of the inner-product matrix grew large. They therefore performed singular value decomposition truncation, retaining dominant singular values to reduce conditioning while pruning low-contributing nodes. The authors’ numerical experiments confirmed that truncation stabilized the pseudoinverse computation when the condition number increased, and demonstrated that theoretical flexibility required clear numerical control.
For condition increment scenarios, the researchers incorporated stochastic adaptive Fourier decomposition to pretrain Blaschke nodes from representative samples and filtered them using Fisher scores to preserve class discriminability. This two-step strategy addressed covariate shift by constructing nodes that reflected domain-invariant structure while suppressing weak discriminators. The decision to combine SAFD with statistical feature ranking implicitly balanced computational burden against robustness; direct SAFD on full datasets would have been prohibitively expensive.
They evaluated the method on a bearing dataset from the University of Paderborn and a bevel gearbox dataset from Hunan University. In static classification tasks, BLM achieved average accuracies exceeding several shallow baselines including BNGBS, KSVM, RF, HD, and MLP. More revealing were the continual learning experiments: across data, class, and condition increments, BLM maintained high diagnostic accuracy while many comparison models exhibited pronounced degradation. The Greville-based updates consumed minimal time relative to deep continual learning frameworks, whose runtimes increased substantially with task progression. The pattern suggests that embedding incremental logic in algebraic updates, instead of gradient-based rehearsal, constrains forgetting without incurring large computational penalties.
To summarize, Professor Junsheng Cheng and colleagues developed a new mathematically structured continual learning classifier tailored to mechanical fault diagnosis. Indeed, it can be considered beyond a new classifier for bearings or gears and reframes mechanical fault diagnosis as approximation within a structured analytic function space. The authors reduce learning to basis selection and coefficient estimation in a domain with explicit geometric constraints by grounding the classifier in a Blaschke expansion theorem. That move shifts part of the burden from empirical tuning to functional analysis. Continual learning in industrial diagnostics often struggles with two competing risks: catastrophic forgetting and structural overgrowth. Models that retrain on new tasks may overwrite earlier representations; models that expand indiscriminately accumulate redundant parameters. The dynamic structure of BLM, combined with SVD truncation, addresses both pressures. Expansion proceeds only when fit falls below threshold, and truncation removes low-contributing components. The result is not a frozen architecture, yet it is not unbounded growth either. The link between approximation residual energy and basis construction, inherited from Blaschke theory, gives this process a conceptual anchor.
The SAFD-based pre-initialization for condition increments carries a second implication. Mechanical systems rarely operate under identically distributed conditions and by constructing Blaschke nodes that approximate the essential structure of stochastic signals and then filtering them through Fisher scores, the method ties domain generalization to signal decomposition itself. If the selected nodes encode invariant structure across operating regimes, classification stability under covariate shift becomes a structural property, not an afterthought. One should not overstate universality. The approach relies on manual feature extraction and Fisher-based selection, which introduces dependency on feature engineering quality. Its performance in end-to-end raw-signal learning contexts remains an open question. Still, the experimental evidence across bearing and gearbox datasets indicates that, within the chosen feature space, the Blaschke framework sustains high accuracy under sequential task updates. That balance of theory and efficiency makes it a compelling alternative for resource-constrained diagnostic systems.


Reference
Xianbin Zheng, Zhengyang Cheng, Junsheng Cheng, Chitin Hon, Yu Yang, Blaschke learning machine: A novel and efficient continual learning classifier toward intelligent fault diagnosis, Mechanical Systems and Signal Processing, Volume 239, 2025, 113350,