Significance
Modern high-performance computing is moving toward architectures built on massive parallelism, instead of depending on further improvements in individual transistor performance. With device miniaturization approaching fundamental physical limits and , integrating larger numbers of cores onto a single chip has become the dominant strategy for sustaining computational growth. Graphics processing units (GPUs), especially those designed for artificial intelligence workloads, are a prime example. However, thermal management is arising as a real limitation and this is because the concentration of power dissipation within densely packed functional units leads to spatially heterogeneous temperature fields, where localized hot spots emerge and evolve dynamically in response to workload fluctuations. These thermal gradients directly influence device reliability, operational stability, and long-term degradation. As cooling strategies approach practical limits, sustaining performance increasingly depends on predictive models that can resolve fine spatial and temporal temperature variations across large-scale chips. Classical numerical approaches, including finite element, finite volume, and finite difference methods, remain the reference standard for thermal analysis due to their physical fidelity. However, their computational burden scales poorly with system size and resolution, which make them not suitable for real-time applications. Other methods were tried to reduce the cost by simplifying the physics or introducing surrogate representations such as circuit-based thermal models which can achieve speed through coarse spatial aggregation but may miss intra-unit hot spots and can approximate heat transfer pathways in a coarse way. Also, purely data-driven methods, such as neural networks, can provide efficiency, but they lack enforcement of the underlying equations, which can reduce confidence in predictions outside the training regime and make interpretation less direct.
Physics-based reduced-order modeling is currently emerging as a promising middle ground with proper orthogonal decomposition (POD), combined with Galerkin projection (GP), providing a structured way to reduce dimension but in the same time retain the underlying physics of heat transfer. Earlier implementations have demonstrated that such models can achieve high accuracy with a small number of modes when applied to systems with relatively few cores. The difficulty arises when extending these methods to architectures with thousands of interacting heat sources. Training such models becomes prohibitively expensive, as the number of possible power configurations grows rapidly. The central challenge, then, lies in preserving the efficiency and accuracy of physics-enforced reduced-order models while making them scalable to the size and complexity of modern many-core GPUs. In a recent research paper published in Structural and Multidisciplinary Optimization, Professor Lin Jiang from the College of Information Science and Engineering at Northeastern University in China and Professors Yu Liu & Ming-Cheng Cheng from the Department of Electrical and Computer Engineering at Clarkson University developed a local ensemble POD-GP thermal modeling method that combines domain truncation with reusable generic sub-models. The new approach is built around a different treatment of training locality. The underlying strategy begins by reconsidering how training data are generated and how the domain of the problem is represented. Instead of constructing a single global model or even assembling multiple full-domain models for individual power sources, the approach partitions the chip into a set of power source blocks, each representing one or several functional units. For each block, the thermal response is characterized independently. The key conceptual shift is that thermal influence from a localized source attenuates with distance, so the full chip does not need to be included in every training problem. By exploiting this behavior, the researchers truncate the computational domain around each power source block, restricting training to a localized region where temperature variations remain significant. This choice directly reduces the number of spatial degrees of freedom required in the simulations used to generate training data.
The authors estimated thermal length scales by analyzing how temperature decays away from a heat source, and the domain is extended to several multiples of this length to balance accuracy and efficiency. The analysis shows that extending the domain to approximately five thermal lengths captures the majority of the thermal contribution while avoiding unnecessary computational expense. This decision reflects a clear connection between physical behavior and model construction: the spatial extent of the training domain is dictated by heat diffusion characteristics rather than by geometric convenience. Once the research team established localized training domains, they applied POD to temperature fields generated from high-fidelity finite element simulations. The resulting POD modes provide a compact representation of the dominant thermal patterns within each truncated region. They used Galerkin projection to map the heat transfer equations onto this reduced space, producing a set of ordinary differential equations that describe the temporal evolution of modal coefficients. This step ensures that the reduced-order model remains anchored in the physics of heat conduction, avoiding the extrapolation issues associated with purely data-driven methods.
Many functional units within the GPU share identical or nearly identical geometries. Rather than training a separate model for each such unit, the method introduces generic truncated domains. A single trained model can therefore represent multiple identical regions, substantially reducing the total number of models required. For units located less than five thermal lengths from a chip boundary, a distinct truncated domain is trained separately to capture the boundary‑condition variations encoded in the finite‑element–generated temperature fields. In the case examined, a system comprising hundreds of power source blocks is represented by only a small set of generic models, each reused across multiple locations with appropriate spatial mapping. The assembled model reconstructs the global temperature field by superposing the contributions from all localized models. Because the underlying heat transfer process is linear within the operating temperature range considered, this superposition remains valid. The approach therefore combines localized accuracy with global coverage, without incurring the cost of full-domain simulations for every configuration. When applied to a large GPU architecture with more than ten thousand cores, the method produces detailed spatiotemporal temperature predictions that closely match those obtained from full finite element simulations. At the same time, the computational cost is reduced by several orders of magnitude. The model captures the emergence and evolution of dynamic hot spots across the chip, resolving fine spatial features that would be inaccessible to coarser modeling approaches.
The new approach of Professors Jiang, Liu & Cheng reconciles accuracy and computational efficiency by making locality part of the model architecture, rather than treating it as an after-the-fact simplification. This distinguishes the method from purely data-driven surrogates, particularly in situations where operating conditions deviate from those seen during training. The ability to estimate error based on the eigenvalue spectrum of the POD modes introduces a level of predictability that is often absent in alternative approaches. It provides a quantitative link between model complexity and expected accuracy, which can guide practical implementation. The treatment of repeated structures within the chip further reflects a pragmatic understanding of modern hardware design. Many-core GPUs are characterized by a high degree of structural regularity, and the method turns this repetition into an opportunity for model reuse. The resulting approach enables detailed thermal analysis at scales that would otherwise be inaccessible for real-time or near-real-time applications. This has implications for dynamic thermal management strategies, where rapid prediction of temperature distributions is essential for controlling power and performance. Also, while the study focused on a specific GPU architecture, the underlying ideas could, in principle, extend to other large-scale integrated systems.
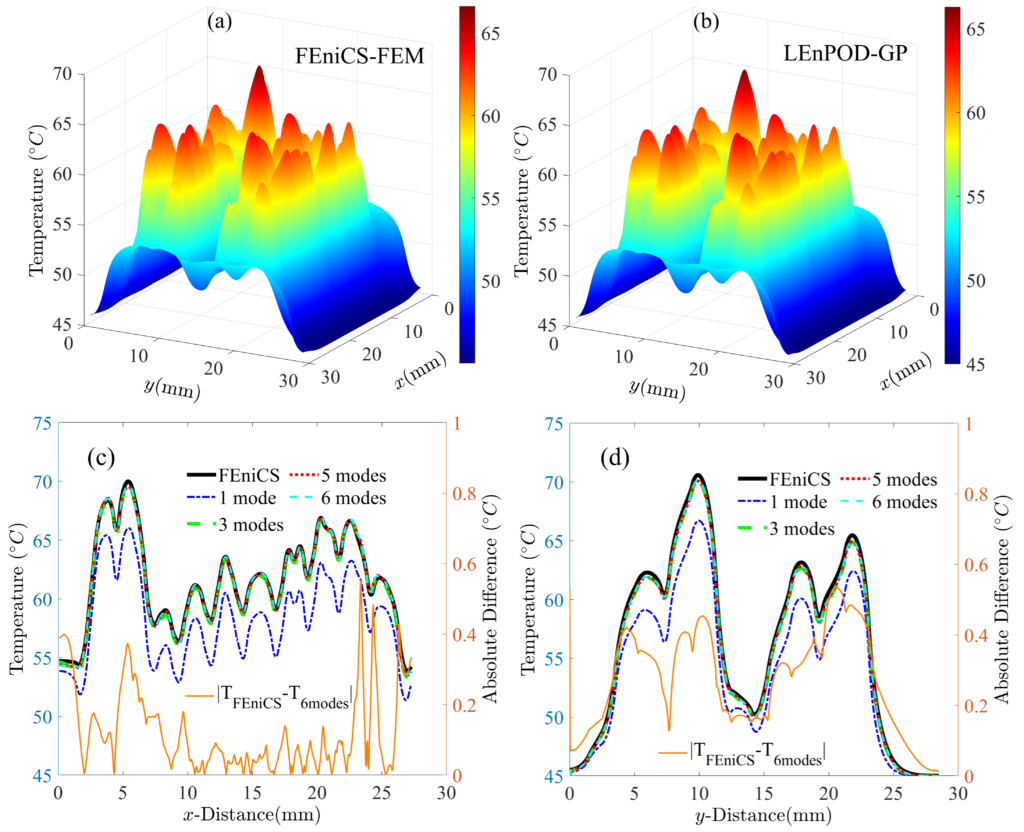
FIGURE LEGEND: Temperature maps of the Tesla Volta GV100 GPU at an instant in time calculated using (a) the finite element (FEniCS‑FEM) method and (b) the local ensemble POD‑GP (LEnPOD‑GP) model with six modes per truncated domain. Temperature profiles along the (c) x and (d) y directions through the high‑peak temperatures predicted by FEniCS‑FEM and LEn‑POD‑GP, along with the deviation of LEn‑POD‑GP from FEniCS‑FEM. CREDIT: Struct Multidisc Optim 68, 235 (2025). https://doi.org/10.1007/s00158-025-04165-x



Reference
Jiang, L., Liu, Y. & Cheng, MC. Effective thermal modeling for large-scale many-core GPUs using local physics-based data-learning approach. Struct Multidisc Optim 68, 235 (2025). https://doi.org/10.1007/s00158-025-04165-x
Go to Journal of Structural and Multidisciplinary Optimization